Router Architecture (Fallbacks / Retries)
High Level architecture
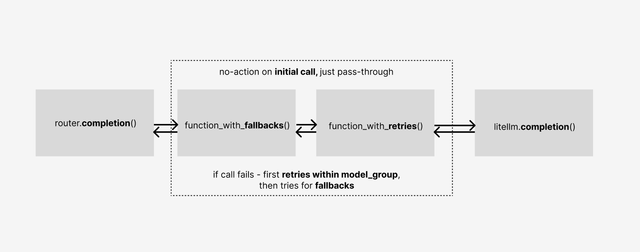
Request Flow
User Sends Request: The process begins when a user sends a request to the LiteLLM Router endpoint. All unified endpoints (
.completion,.embeddings, etc) are supported by LiteLLM Router.function_with_fallbacks: The initial request is sent to the
function_with_fallbacksfunction. This function wraps the initial request in a try-except block, to handle any exceptions - doing fallbacks if needed. This request is then sent to thefunction_with_retriesfunction.
function_with_retries: The
function_with_retriesfunction wraps the request in a try-except block and passes the initial request to a base litellm unified function (litellm.completion,litellm.embeddings, etc) to handle LLM API calling.function_with_retrieshandles any exceptions - doing retries on the model group if needed (i.e. if the request fails, it will retry on an available model within the model group).litellm.completion: The
litellm.completionfunction is a base function that handles the LLM API calling. It is used byfunction_with_retriesto make the actual request to the LLM API.
Legend
model_group: A group of LLM API deployments that share the same model_name, are part of the same model_group, and can be load balanced across.